6. 并行策略¶
6.1 数据并行(Data Parallel)
6.2 流水线并行(Pipeline Parallel)
6.3 张量并行(Tensor Parallel)
6.4 整合:3D并行(3D Parallel)
6.5 零冗余优化器(ZeRO)
本文将详细介绍CoLLiE使用的并行策略,并行策略是让模型训练突破单张显卡计算和存储上限的不同方法,CoLLiE支持的并行策略包括:数据并行 DP、流水线并行 PP、张量并行 TP、3D并行(对上述三者的整合)、零冗余优化器 ZeRO,其简要特征如下表所示。在本文中,我们将从前向传播、反向传播、代码实现等角度,对这些并行策略展开详细介绍。
名称 |
简称 |
切分数据 |
切分模型 |
切分梯度 |
切分状态 |
补充说明 |
|---|---|---|---|---|---|---|
数据并行 |
DP |
✔ |
✘ |
✘ |
✘ |
每个卡保留全部的模型参数、回传梯度、优化器状态 |
流水线并行 |
PP |
✘ |
✔ |
— |
— |
每张卡保留模型的不同层,存在 bubble time 的问题 |
张量并行 |
TP |
✘ |
✔ |
— |
— |
每张卡保留每层的一部分,注意 先列切分 再行切分 |
(整合) |
3D |
✔ |
✔ |
— |
— |
结构上,先PP,再TP,通过在每dp_size张卡保留相同切分,实现DP |
零冗余优化器 |
ZeRO1 |
✔ |
✘ |
✘ |
✔ |
在DP基础上,每张卡保留不同参数的优化器状态,直接切,均匀分 |
ZeRO2 |
✔ |
✘ |
✔ |
✔ |
在ZeRO1基础上切分梯度,每张卡保留不同参数的优化器状态和梯度 |
|
ZeRO3 |
✔ |
✔ |
✔ |
✔ |
在ZeRO2基础上切分模型,每张卡保留不同参数及对应其他内容 |
6.1 数据并行(Data Parallel)¶
数据并行(Data Parallel,简称 DP)是最简单的并行方案。严格来说,DP只能说实现了分布式训练,并不能真的实现模型并行;虽然提升了模型训练效率,但是在存储上存在巨大的冗余,无法解决单张卡装不下整个大模型的问题。
前向传播 如下左图(或右图)所示,假设我们有1个大语言模型,基于Transformer架构,包括N层自注意力模块(蓝色)、输入层和输出层(红色),也有1台服务器上的K张显卡。DP首先让每张卡保留相同的完整的模型,接着在每次前向传播时,将不同batch的数据分配给不同的卡;如下左图所示,K张显卡同时计算K个batch,每张显卡彼此之间独立计算,没有通信与同步。
反向传播 如下右图所示,前向传播之后,每张卡上产生了对应数据的损失。接着,和前向传播相同,每张卡对各自的损失进行反向传播计算梯度;但是每张卡在梯度计算后不会立刻进行更新,而是先通过通信对梯度取平均,再通过梯度下降更新各自参数,由此保证每张卡上模型参数仍然相同,在下次前向传播不同数据仍然面对相同的模型拷贝。


代码实现 CoLLiE 通过指定 CollieConfig.dp_size 控制数据并行粒度,即有多少张显卡存储模型拷贝;如下方代码所示,对于运行在4卡上的程序,设置CollieConfig.dp_size=4,就可以实现DP。
from collie.config import CollieConfig
config = CollieConfig.from_pretrained('meta-llama/Llama-2-7b-hf')
config.dp_size = 4
config.pp_size = 1
config.tp_size = 1
6.2 流水线并行(Pipeline Parallel)¶
流水线并行(Pipeline Parallel,简称 PP),最早出自论文 GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism。PP将模型横向切分,将参数分摊到不同的卡上,缓解了DP存储冗余的问题,但在时间开销上存在 bubble time 的问题,需要通过 micro_batch 和 1F1B 等技巧改进其初始效果。
前向传播 如下左图所示,同样是对于N层的大语言模型,K张显卡;PP利用当前大模型由若干相同的自注意力层组成的特点,将模型按照层堆叠的方向切分(左图只是演示,也可以多层对应一个切分),将不同切分分配到不同的显卡上。如此一来,每张显卡只存储模型的一部分,由此就充分利用了多张显卡的存储能力,扩充了服务器所能承载的模型参数上限,真正实现了模型的并行。在前向传播过程中,每张卡只负责对应层的计算,以及将计算结果传输到存储下一层的显卡上。
反向传播 和前向传播类似,PP在反向传播过程中,每张卡也只计算对应层的梯度,以及将梯度传输到存储上一层的显卡上,计算完梯度后即可以立刻更新参数。相比于DP需要在反向传播过程中,同步每层的梯度,PP设备间的通信更小;但是PP设备间存在数据上的依赖:前向传播时,顶层等待底层的计算结果,反向传播时,底层等待顶层的回传梯度,由此产生的闲置时间被称为 bubble time。
由此,GPipe的作者提出,通过将大的batch切成小份的micro_batch,例如右上图所示,将1个batch变成4个microbatch。在前向传播和反向传播两个阶段内部提升显卡的利用率:第1个microbatch在第1个显卡上前向传播后,空出第1个显卡给第2个microbatch,同时在第2个显卡上继续计算;全部前向传播后,进行反向传播;第4个microbatch先在第4个显卡上反向传播,空出第4个显卡后给第3个microbatch,同时在第3个显卡上继续回传;全部回传结束后,每个显卡内部对所有microbatch的梯度求平均再做更新。

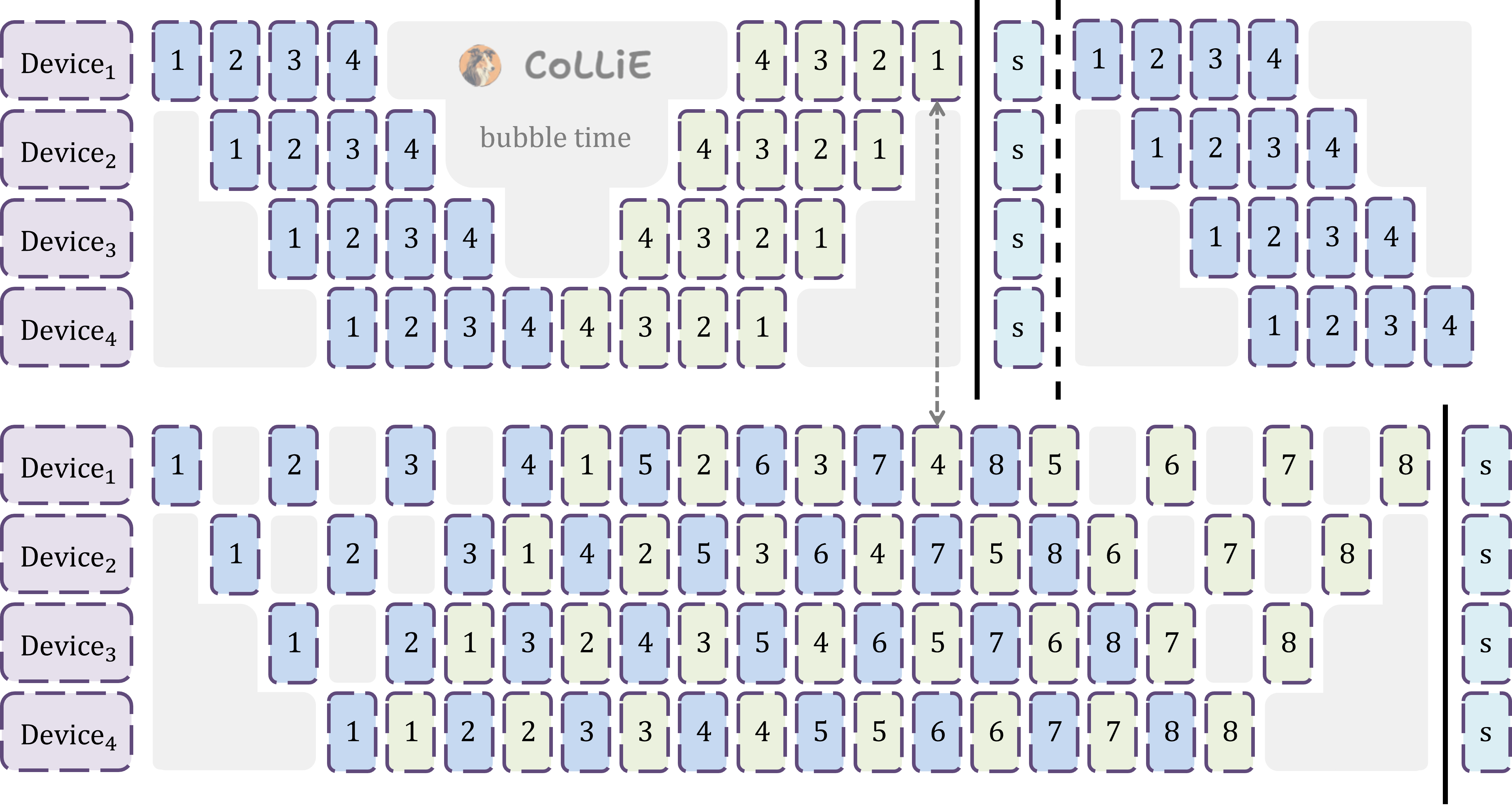
策略改进 如前文所述,PP的特点在于:一方面,横向切分,将不同的层放到不同的显卡上;另一方面,显卡之间存在数据依赖,只能依次执行,由此产生了 bubble time。为了进一步缓解 bubble time 的问题,后来的研究人员提出了 1F1B 策略,如右下图所示,这也是CoLLiE支持的PP实现方法。1F1B的核心思想是:对于每个microbatch,执行一次前向传播后,立即执行一次反向传播,但不立刻更新梯度;后一个microbatch利用前若干个microbatch前向/反向传播的空隙,进行前向/反向传播。
观察右上图(GPipe)和右下图(1F1B)可以发现,一方面,上下两张图的bubble time是一样的,但是1F1B可以在相同的bubble time开销下,执行更多的microbatch,即 1F1B相较于GPipe提升了显卡的利用率,并且microbatch越多,1F1B在利用率上的优势更显著。另一方面,如虚线箭头所示,同样执行4个microbatch,1F1B并没有在GPipe之前完成,即 1F1B相较于GPipe实际消耗时间是一样的;GPipe只是提升了资源的利用率,在同等耗时内,执行了后续若干microbatch的计算过程。
代码实现 CoLLiE 通过指定 CollieConfig.pp_size 控制流水线并行粒度,即将模型横向切分为多少份,并分别存储;如下方代码所示,对于运行在4卡上的程序,设置CollieConfig.pp_size=4,就可以实现PP。由于 PP每次梯度更新对应的数据条目数量 等于 microbatch大小 乘上 每次更新对应的microbatch数量,所以 对于PP train_batch_size = train_micro_batch_size * gradient_accumulation_steps。
除此之外,参数 CollieConfig.pp_partition_method 还可以控制PP切分方式:默认切分方式 "parameter",保证每张卡上参数量近似相等;"uniform",保证每张卡上层数近似相等;"type:[regex]",保证与"[regex]"正则匹配(不区分大小写)的层在每个切分上的数目近似相等,例如"type:transformer"使得每个切分上Transformer层的数目接近。
from collie.config import CollieConfig
config = CollieConfig.from_pretrained('meta-llama/Llama-2-7b-hf')
config.dp_size = 1
config.pp_size = 4
config.tp_size = 1
config.train_micro_batch_size = 2
config.gradient_accumulation_steps = 2
6.3 张量并行(Tensor Parallel)¶
张量并行(Tensor Parallel,简称 TP),最早出自论文 Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism。TP将模型纵向切分,即 让每张卡都具有模型每一层的每一切片。如下图所示,对于Transformer模型的每个部分,例如输入映射、自注意力模块、前馈网络模块、输出映射,TP都给予了特定的切分方法,整体上大致遵循“先列切分,再行切分”的策略。
前向传播 对于自注意力模块,TP将原始的多头的自注意力,按照注意力头方向切分,每张卡上只安放几个注意力头。从参数角度,TP首先将Wq、Wk、Wv在列方向上切分(column-wise split,由于线性变换在实现上是输入向量乘上参数矩阵的转置,因而列方向就是特征维度方向),分配到对应的卡上,与之相对,TP最后将Wo在行方向上切分(row-wise split,对应到矩阵乘法上就是让切分的每部分特征维度,乘上对应的变换矩阵分块,然后再加起来)。从计算角度,如下图所示,TP首先将输入的特征序列x,复制多份到不同的卡上,基于列切分的Wq、Wk、Wv进行自注意力计算,得到不同头的自注意力结果,再基于切分的Wo进行线性变换,最后加在一起就得到了自注意力模块的输出。
对于前馈网络模块,最简单的FFN包括一个维度放大的线性变换Wup、中间激活函数(例如图中的gelu)、一个维度缩小的线性变换Wdown。对此,TP仍然采用“先列切分,再行切分”的策略,从参数角度,将Wup在输出特征维度,即 列方向上切分,将Wdown在输入特征维度,即 行方向上切分。从计算角度,对于FFN的输入特征序列x,首先同样复制多份到不同的卡上,基于不同的Wup切分进行线性变换,接着让变换结果通过激活函数(这一步是逐元素的操作,element-wise,无需考虑并行),最后基于不同Wdown切分再线性变换并加在一起,就得到了前馈网络模块的输出。
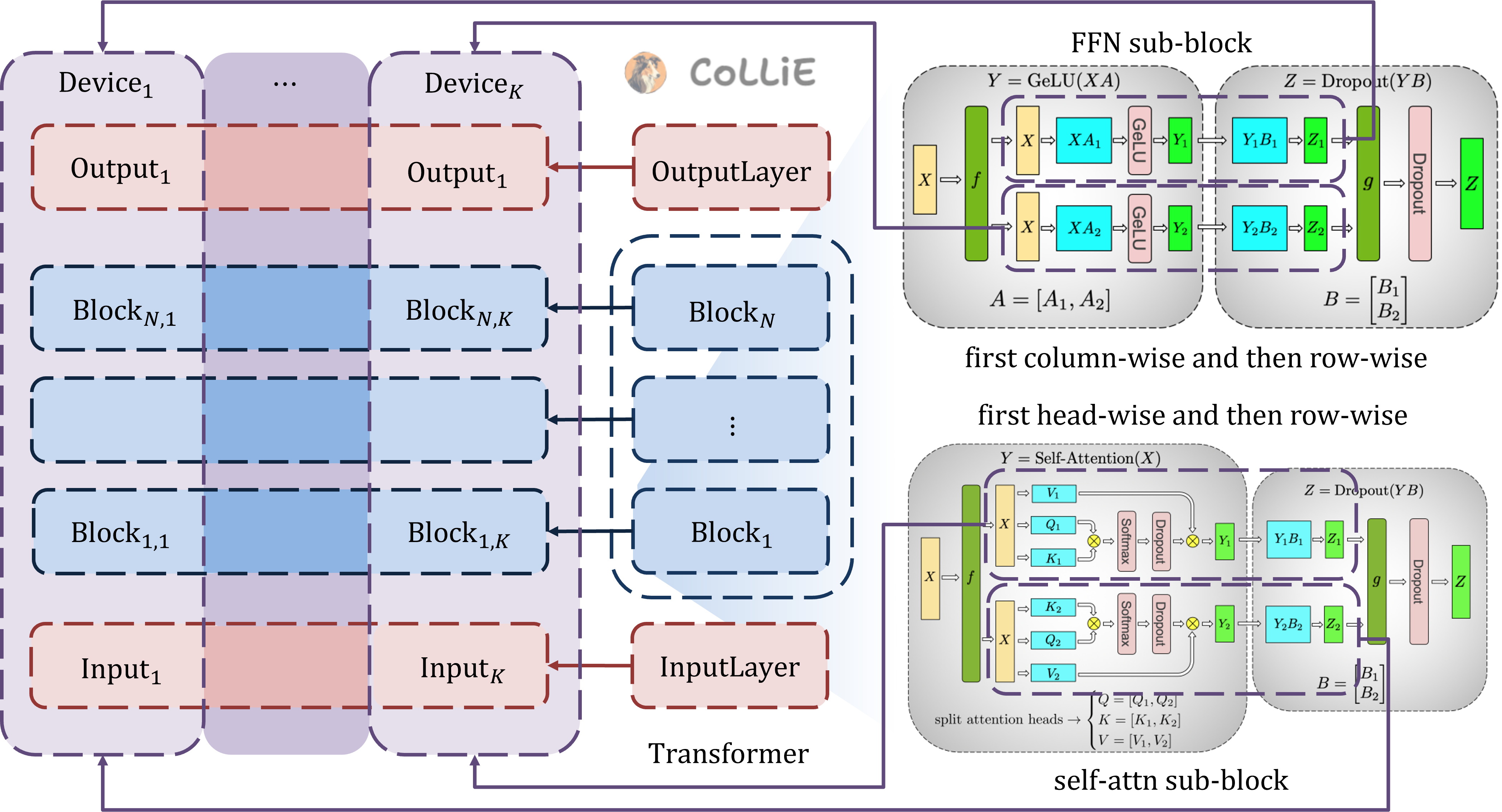
反向传播 以上基本是TP前向传播的完整流程了,需要注意的一点是,在这个过程中,虽然在特征维度方向上特征序列几经拆分合并,但每个Transformer层内部的梯度计算都是独立且完整的,通过前后各一个同步棒分法和聚合:在正向传播的过程中,数值复制分发给各路列并行,列并行结束后对应元素即进入行并行,在行并行结束后又通过求和聚合起来;而在反向传播的过程中,梯度通过复制首先分发给各路行并行,接着内部各自独立地反向传播从行并行部分至列并行部分,在列并行梯度求完后通过求和又重新聚合起来。
此外需要注意的是,对于输入映射和输出映射,CoLLiE都采用了列并行的方式,将输入输出映射的矩阵按照输出维度的方向切分至不同的卡;由于这个列并行结束后并没有行并行,所以输入输出映射的结果直接在列并行后就合并回原来的完整形状。相比于流水线并行PP,张量并行TP尽量做到server内部通信,不存在PP的bubble time问题,由此在batch_size较小时具有更明显的优势。关于TP还需要补充解释两点。一,CoLLiE所涉及的TP由于切分维度只有一个,因而又称为1D TP,对于更复杂的TP,我们不做过多探讨,这里的TP就默认为1D TP。二,有些文献中直接将张量并行TP称为模型并行(model parallel),在本教程中将流水线并行PP和张量并行TP都视为模型并行,即将模型参数分摊到各个不同的显卡上并行计算,的一种方法。
代码实现 CoLLiE 通过指定 CollieConfig.tp_size 控制张量并行粒度;如下方代码所示,对于运行在4卡上的程序,设置CollieConfig.dp_size=4,就可以实现TP。
from collie.config import CollieConfig
config = CollieConfig.from_pretrained('meta-llama/Llama-2-7b-hf')
config.dp_size = 1
config.pp_size = 1
config.tp_size = 4
6.4 整合:3D并行(3D Parallel)¶
数据并行、流水线并行、张量并行之间是可以相互兼容促进的,DP、PP、TP 的整合被称作3D并行。在CoLLiE中,3D并行的实现就是在模型初始化阶段,顺次完成三种并行对模型参数的切分拷贝。具体顺序是:先顺着层的方向横向切分pp_size份,实现PP;在每个PP切分内部,再对每个层做纵向切分tp_size份,实现TP;两次切分完,最后对于每个两次切分后的切片 拷贝dp_size份,由此就实现了模型的3D并行,如下图所示。
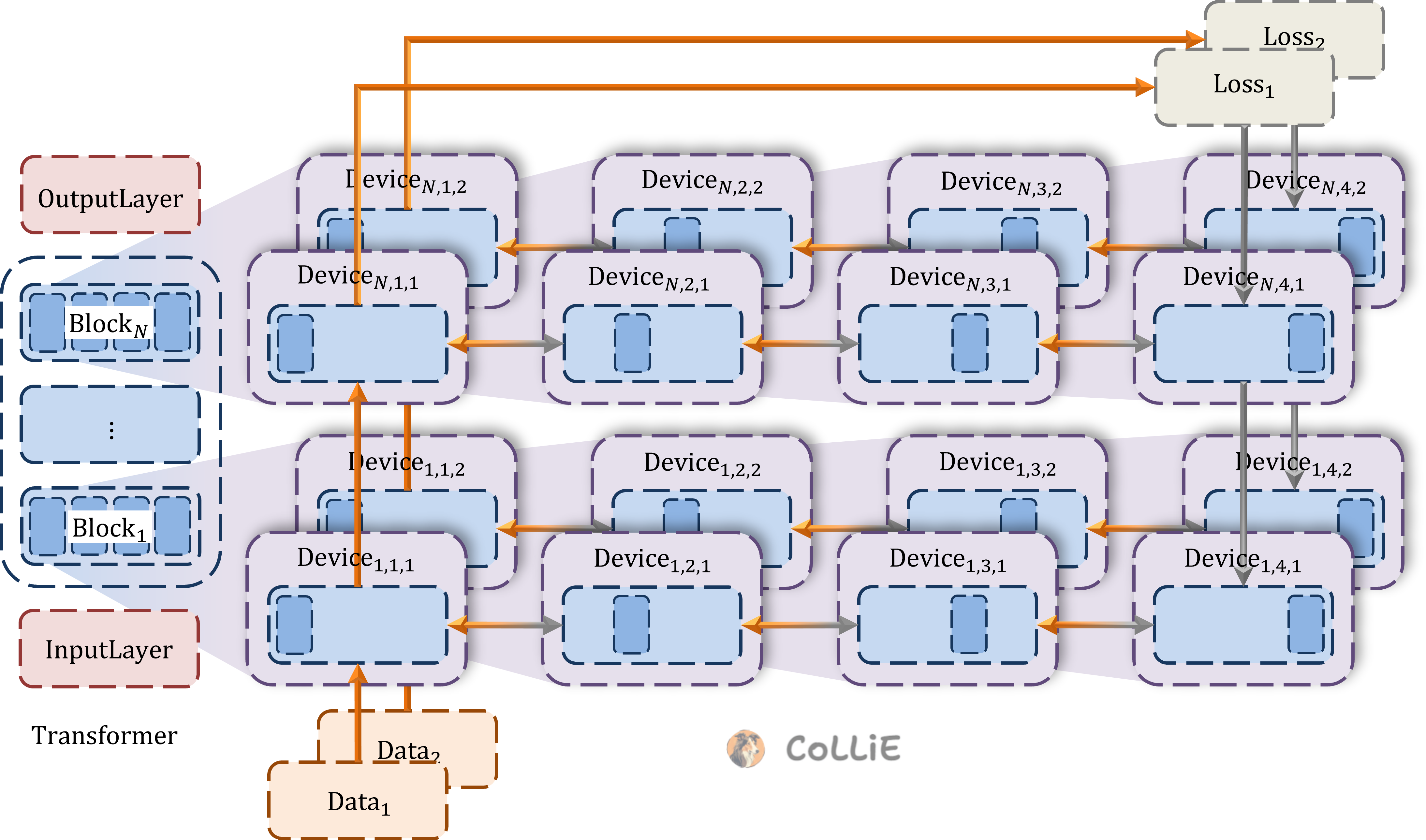
3D并行的代码与之前的DP、PP、TP完全相同,换言之,之间单纯的DP、PP、TP也可以看做3D并行的一个特例。此外,需要注意的是,在CoLLiE中,如果PP并行数量pp_size和TP并行数量tp_size的乘积达不到模型运行的总显卡数量,CoLLiE会自动将dp_size设定为卡的数量除以pp_size再除以tp_size。除了上的并行方案外,CoLLiE还可以通过设置activation checkpoint来节省显存,即在正向传播的过程中,仅在某几层保留计算的中间结果activation,而在反向传播的过程中,如果传到某一层发现activation缺失,那么模型会自动从向下最临近的保留activation的那一层将activation重新正向传播计算得到。
from collie.config import CollieConfig
config = CollieConfig.from_pretrained('meta-llama/Llama-2-7b-hf')
config.dp_size = 2
config.pp_size = 2
config.tp_size = 4
6.5 零冗余优化器(ZeRO)¶
零冗余优化器(Zero Redundancy Optimizer,简称 ZeRO),最早出自论文 ZeRO: Memory Optimizations Toward Training Trillion Parameter Models,是 数据并行和模型并行的结合。ZeRO包括两个部分:ZeRO-DP,负责在数据并行的基础上进一步优化显存利用(ZeRO-powered data parallel),ZeRO-R,负责优化冗余状态存储(residual state memory,与model state memory相对,即参数、梯度、优化器状态之外的存储,本教程不做过多讨论);其中,ZeRO-DP又包括三个优化阶段:ZeRO1,切分优化器状态(state partitioning),ZeRO2,增加切分回传梯度(add gradient partitioning),以上相比数据并行不额外增加通信,ZeRO3,增加切分模型参数(add parameter partitioning)。不同于PP和TP,ZeRO对每个模块直接切、均匀分。
基本思想 不同于PP和TP,ZeRO的出发点在于优先降低优化器状态的存储开销;实现方法是对每个Transformer的每一层,每一层每个模块的参数,以及其对应优化器状态,都直接切、均匀分。ZeRO发现大模型训练的过程中,开销最大的不是模型参数或回传梯度的存储(回传梯度大小和模型参数大小相同,对应下图中每个模块靠左的两个子模块),而是优化器的状态,例如Adam中的参数副本、一阶动量、二阶动量(这些的大小都是模型参数大小的4倍,对应下图中每个模块中靠右的子模块);也因此ZeRO相较于原始的DP的第一个改进就是将优化器状态切分至不同显卡,而后再以相同的方式切分回传梯度、模型参数。
而论及ZeRO的切分方式,以ZeRO3为例,如下图所示,在模型初始化阶段,首先将每个模型的每个部分都均分到了每一张卡上,这样虽然每张卡都不能看到完整的一块参数,但保有每块参数的一个片段。在前向传播阶段,由于ZeRO建立在DP的基础上,每张卡会被分配不同的数据,当输入传输到任意一层的时候,由于当前的显卡没有完整参数,都必须要从其他显卡借调对应的参数补全当前的参数进行运算,并在完成当前计算后立刻释放,仅保留当前显卡原来持有的参数片段。类似地,在反向传播阶段,每张卡会接受来自损失的梯度回传,同样需要从其他显卡借调对应参数补全并完成梯度和优化器状态的更新,在更新的同时对来自不同数据的梯度取均值,在更新之后同样释放显卡上本来没有的参数、梯度和优化器状态。

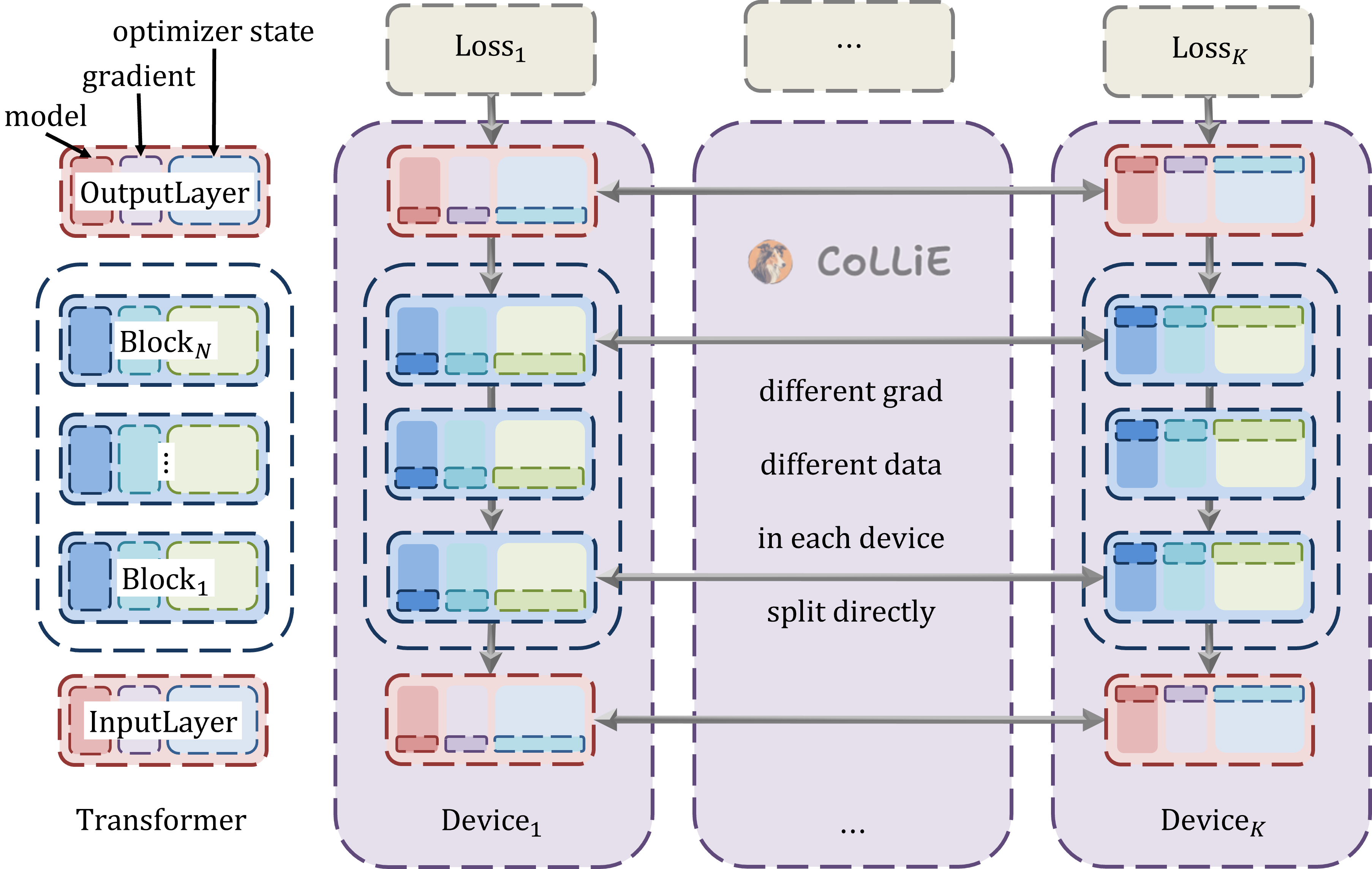
三个阶段 如果将最原始的DP称作ZeRO0,那么ZeRO1、ZeRO2、ZeRO3的目的便是依次在前者的基础之上改进显卡的利用率。如前文所述,ZeRO1首先切分优化器状态,也因此ZeRO1仅在反向传播时与DP不同:在更新完各自数据对应的梯度后,需要在同步梯度的同时,更新对应显卡的优化器状态片段。此外,由于ZeRO2/3存在对回传梯度和模型参数的切分,也只有ZeRO1可以与PP相兼容。在此基础上,ZeRO2继续切分回传梯度,每张显卡计算完当前梯度并更新参数后,仅保留当前优化器片段对应梯度片段;由此,ZeRO2在不增加通信开销的基础上,进一步降低显存占用。最后ZeRO3切分模型参数,完成了上述所有内容的切分:在前向传播时,每算到一层收集对应参数计算;在梯度回传时,同步更新后,各显卡仅保留对应优化器和梯度片段。
代码实现 在CoLLiE中,不同于PP,ZeRO的设置被放在config.ds_config当中,通过 在 "zero_optimization" 字段传入 {"stage": 3},即可开启ZeRO3,如下所示;由于设置方法与deepspeed相同,关于ZeRO的更多参数设定,详见 deepspeed官方文档。
from collie.config import CollieConfig
config = CollieConfig.from_pretrained('meta-llama/Llama-2-7b-hf')
config.dp_size = 1 # 自动转化为全部卡的数量
config.pp_size = 1
config.tp_size = 1
config.ds_config = {
"fp16": {"enabled": True},
"monitor_config": {
"enabled": True,
"tag": f"tutorial-lr_0.00001-epoch_3",
"wandb": {
"enabled": True,
"team": "collie_exp",
"project": "llama_alpaca",
"group": f"llama2_7b",
}
},
"zero_optimization": {"stage": 3},
}