3. 基础模块¶
3.1 CoLLiE 的 Config 模块
3.2 CoLLiE 的 Dataset 和 Model
3.3 CoLLiE 的 Evaluator 和 Metric
3.4 CoLLiE 的 Trainer 模块
3.1 CoLLiE 的 Config 模块¶
在tutorial-1的代码示例中,除了最开始的import部分,第一个用到的CoLLiE模块就是CollieConfig。CoLLie 的配置模块 CollieConfig 是整个 CoLLiE 的核心,CoLLie 的高度集成化归功于对 CollieConfig 配置文件的集中统一管理。CoLLiE 几乎所有的组件都受到 CollieConfig 的控制,包括模型架构(CollieConfig.model_config)、并行策略(CollieConfig.dp_size, CollieConfig.pp_size, CollieConfig.tp_size)、微调方法(CollieConfig.peft_config)等;CollieConfig 涉及的全部配置参数 以及 对应的功能描述 如下表所示。
名称 |
描述 |
|---|---|
seed |
随机数种子,整数 默认 42 |
dp_size |
数据并行粒度,整数 默认 1,详见 tutorial-6 |
pp_size |
流水线并行粒度,整数 默认 1,详见 tutorial-6 |
tp_size |
张量并行粒度,整数 默认 1,详见 tutorial-6 |
pp_partition_method |
流水线并行切分方式,默认 'parameters',详见 tutorial-6. |
train_epochs |
训练 epoch 数量,整数 默认 100 |
eval_per_n_steps |
多少 step 一次评测,整数 默认 0 |
eval_per_n_epochs |
多少 epoch 一次评测,整数 默认 0 |
train_micro_batch_size |
训练 batch 大小,整数 默认 1(流水线并行:作为 micro_batch 大小,详见 tutorial-6) |
gradient_accumulation_steps |
多少 backward 一次 step,整数 默认 1(流水线并行:决定 train_batch 大小,详见 tutorial-6) |
eval_batch_size |
测试 batch 大小,整数 默认 1 |
checkpointing |
是否使用 activation checkpointing,默认 True |
use_flash |
是否使用 flash attention 进行自注意力加速,默认 True |
dropout |
dropout 大小,浮点数 默认 0.0 |
init_method |
参数初始化方法,可选值 'none'(默认)、'normal'、'kaiming_normal'、'kaiming_uniform’等 |
low_cpu_mem_usage |
是否在模型初始化阶段尝试减少 CPU 占用,默认 True |
ds_config |
指定 deepspeed 参数,字典型 或 json文件名,涉及零冗余优化器,详见 tutorial-6 |
model_config |
指定模型架构相关的配置项,默认 transformers.PretrainedConfig() |
peft_config |
指定模型参数高效微调方法,默认 peft.PeftConfig() |
quantization_config |
指定模型量化方法,默认 transformers.BitsAndBytesConfig() |
由于在 CollieConfig 的所有的配置项中,模型架构相关的配置是较为繁琐但又相对固定的,因此 CollieConfig 提供了与 transformers.PretrainedConfig 类似的 from_pretrained 方法初始化 CollieConfig,并对 CollieConfig.model_config 赋值。例如,在tutorial-1中,首先明确模型架构为"meta-llama/Llama-2-7b-hf",接着使用 CollieConfig.from_pretrained 快速初始化,再定义并行相关参数(需要注意的是,由于是4卡运行,虽然三个并行粒度全部设为1,但数据并行粒度dp_size会自动设为4,详见 tutorial-6),最后定义训练相关参数,如 训练轮数、评测频率、batch大小。
from collie import CollieConfig
model_name_or_path = "meta-llama/Llama-2-7b-hf"
config = CollieConfig.from_pretrained(model_name_or_path)
config.dp_size = 4
config.pp_size = 1
config.tp_size = 1
config.train_epochs = 3
config.train_micro_batch_size = 32
config.gradient_accumulation_steps = 1
config.ds_config = {
"fp16": {"enabled": True},
"monitor_config": {
"enabled": True,
"tag": f"tutorial-lr_0.00001-epoch_3",
"wandb": {
"enabled": True,
"team": "collie_exp",
"project": "llama_alpaca",
"group": f"llama2_7b",
}
},
"zero_optimization": {"stage": 3},
}
3.2 CoLLiE 的 Dataset 和 Model¶
在tutorial-1中,在通过 CollieConfig 制定配置参数之后,接下来就是依次加载 数据集 Dataset、初始化 模型 Model;二者也是本小节将要详细介绍的 CoLLiE 模块。
首先介绍的是 CoLLiE 自定义的模型基类 CollieModelForCausalLM。我们知道 CoLLiE 最关键的功能是同时实现了对多种并行策略的支持,但是 张量并行 和 流水线并行 对模型架构的严格要求,普通的 torch.nn.Modul 或 transformers.PreTrainedModel 无法实现上述并行策略;因此,在 CoLLiE 中,我们自定义了支持多种并行方案的模型基类 CollieModelForCausalLM。使用 CoLLiE 训练或评测模型,必须使用 CollieModelForCausalLM 或其子类 初始化模型;如果强行使用 torch.nn.Modul 或 transformers.PreTrainedModel 训练,仅支持 数据并行 和 零冗余优化器。 CollieModelForCausalLM 继承并重写了一些较为流行的模型,例如 LLaMA(LlamaForCausalLM)、MOSS(MossForCausalLM、Moss003MoonForCausalLM)、ChatGLM/ChatGLM2(ChatGLMForCausalLM、ChatGLM2ForCausalLM)、InternLM(InternLMForCausalLM),方便用户直接调用,如下表所示。在重写的过程中,我们保证接口尽可能和 transformers 一致,如下表所示,方便熟悉 transformers 的用户能快速上手使用。
名称 |
描述 |
|---|---|
from_config |
根据config随机初始化模型,config可以是CollieConfig 或 字符串(hf或本地路径) |
from_pretrained |
根据config初始化模型,并通过model_name_or_path找到预训练模型参数权重加载 |
forward |
前向传播函数,输入 input_ids、attention_mask、past_key_values 等字段 |
generate |
生成函数,直接继承自 transformers.generation.utils,用法一致 |
main_input_name |
属性,返回输入必须在forward函数中输入的字段 |
例如,在tutorial-1中,在指定模型类别并初始化 CollieConfig 后,即可以通过 CollieModelForCausalLM.from_pretrained,即这里的 LlamaForCausalLM.from_pretrained,初始化 LLaMA2 模型,并从 huggingface 下载预训练参数并完成加载,加载过程遵循传入的 CollieConfig。
from collie import LlamaForCausalLM
# model_name_or_path = "meta-llama/Llama-2-7b-hf"
# config = CollieConfig.from_pretrained(model_name_or_path, trust_remote_code=True)
model = LlamaForCausalLM.from_pretrained(model_name_or_path, config=config)
在model中,forward函数必须要输入input_ids和attention mask,从而根据输出的logits和标签labels计算loss,然后反向传播、梯度更新。但在实际的训练过程当中,训练任务可以是简单的语言建模,同时也可以是指令微调;而对于后者,不是所有input_ids对应的logits都需要参与loss的计算。除此之外,在测试过程当中,模型的输入也存在一些特殊情况需要考虑。虽然对于生成任务,我们可以直接根据输入让模型续写,但是对于生成形式的分类任务,还需要让模型额外考虑选项等因素。
对于上述两个问题,CoLLiE 提出了 自定义的数据集 CollieDataset,实现自动的数据格式转换。在 CoLLiE 的使用过程中,可以使用 datasets.load_dataset,不一定涉及到 CollieDataset;但是无论如何,都必须要实现输入数据格式的转换,即 将每笔数据转化为字典,并且 该字典的键值 需要与 模型CollieModel 和 评测指标Metric的输入 一致。CoLLiE 定义了三种 CollieDataset,如下表所示:CollieDatasetForTraining/CollieDatasetForPerplexity、CollieDatasetForGeneration、CollieDatasetForClassfication;CollieDataset完整的初始化参数列表如下所示;无论哪种 CollieDataset,在初始化时都需要将数据以一个dict列表的形式输入(每个dict一笔数据),限定了输入数据的形式,从而在训练或测试过程中,CollieDataset向模型和评测指标传递格式对齐的数据dict。
名称 |
描述 |
|---|---|
dataset |
数据,dict列表形式,dict形式取决于CollieDataset类型 |
tokenizer |
PreTrainedTokenizer类型,可以为None,但一般要求输入 |
add_special_tokens |
tokenize参数,是否在tokenize过程中加入特殊token,默认 True |
max_length |
tokenize参数,tokenize过程中截断序列最大长度,默认-1,即不截断 |
shuffle |
dataset参数,是否在构建数据集时打乱顺序,默认 False |
seed |
随机数种子,默认 1024 |
style |
CollieDatasetForClassfication特有参数,默认 "harness" |
对于CollieDatasetForPerplexity,输入的数据dict有两种形式,输出的数据dict只有一种形式。一种输入形式,数据dict只包含一个字段“text”,对应简单的语言建模,在“text”内根据前若干个token预测下一个token。此时输出的“input_ids”、“labels”就是“text”经过tokenizer处理过后的结果,没有错位;“input_ids”输入model计算“logits”,再和“labels”输入metric或者loss_fn。另一种输入形式,数据dict包含两个字段“prompt”和“output”,对应指令微调任务,根据固定的“prompt”续写内容和“output”比较计算损失;此时输出的“input_ids”是“prompt”和“output”拼接后经过tokenizer处理过后的结果,而“labels”虽然与“input_ids”形状一样,但是仅后半部分对应tokenize的“output”,对应“prompt”的前半部分全部设为-100;由此实现了仅有生成部分参与loss_fn的计算,实现了对语言建模和指令微调两种任务形式的兼容。CollieDatasetForPerplexity主要用于训练,所以也命名为CollieDatasetForTraining;测试阶段,尤其是下游任务的评测主要使用后两种CollieDataset。
对于针对生成任务的CollieDatasetForGeneration,输入和输出的数据dict只有一种形式。dataset的输入数据dic包含两个字段“text”、“target”,意图让模型根据“text”输入实现“target”输出。此时dataset的输出数据dict包含“input_ids”、“labels”、“target”,其中,“input_ids”、“labels”是“text”经过tokenizer处理过后的结果,“target”是“target”经tokenizer处理过后的结果;这里的“labels”不在生成任务评测的metric中发挥作用。

对于针对分类任务的CollieDatasetForClassfication,其输入的数据dict只有一种形式,包含输入问题“input”、候选答案列表“output”、答案序号“target”(即正确答案在候选答案列表中的序号),但是输出的数据dict有两种形式,分别对应两种处理方法,harness和helm。harness假设正确答案一定在候选答案中,那么对于这个正确的候选答案,将它和问题拼接得到的句子的困惑度会最小。也因此harness输出的数据dict包含三个字段:“input_ids”、“labels”、“target”,其中,“input_ids”、“labels”是输入数据dict中问题“input”和每个候选答案拼接后tokenize得到的列表,“input_ids”输入model计算“logits”结合“labels”得到每个选项的困惑度打分,“target”和输入数据dict的“target”一致。
而与harness相对,helm不认为正确答案一定存在于候选答案中,直接要求模型在给定问题“input”的条件下预测结果,如果不在候选答案列表“output”则预测结果设为-1。helm输出的数据dict包含四个字段:“input_ids”、“labels”、“output”、“target”,“input_ids”、“labels”只是输入数据dict中问题“input”经tokenizer处理过后的结果,“labels”同样不起作用,“output”是输入数据dict中候选答案列表“output”经tokenizer处理过后的列表,“target”仍然和输入数据dict的“target”一致。关于上述CollieDataset在评测中的具体应用详见下一节,下表简单梳理了不同CollieDataset的功能和输入输出注意事项。
名称 |
描述 |
|---|---|
CollieDatasetForTraining |
所有CollieDataset的基类,行为与CollieDatasetForPerplexity完全相同 |
CollieDatasetForPerplexity |
用于训练或测试LLM输出困惑度的CollieDataset,输入两种形式,输出一种形式 |
CollieDatasetForGeneration |
用于测试LLM执行生成任务效果的CollieDataset,输入一种形式,输出一种形式 |
CollieDatasetForClassfication |
用于测试LLM执行分类任务效果的CollieDataset,输入一种形式,输出两种形式 |
在tutorial-1中,关于Dataset的使用如下所示。这里额外添加一行代码,表示CoLLiEDataset允许通过切片的方式进行数据集切分,切分得到的评测数据集可以传入Evaluator中,用于训练过程的评测。
tokenizer = LlamaTokenizer.from_pretrained(model_name_or_path, padding_side="left")
data = [{
"intput": sample["prompt"].split("### Response:\n")[0] + "### Response:\n",
"output": sample["prompt"].split("### Response:\n")[1] + tokenizer.eos_token
} for sample in load_dataset("crumb/stanford_alpaca_full_prompts")["train"]]
train_dataset = CollieDatasetForTraining(data, tokenizer=tokenizer, max_length=2048)
eval_dataset = train_dataset[:32]
3.3 CoLLiE 的 Evaluator 和 Metric¶
本节将介绍 CoLLiE 中的 评测指标 Metric、评测模块 Evaluator,以及至关重要的,CoLLiE 中 数据集 Dataset、评测指标 Metric、评测模块 Evaluator 之间紧密的对应关系。在CoLLiE中,不同的Evaluator对应不同类型的评测任务,继而匹配不同的Dataset和Metric,如下表所示。Evaluator的eval()对给定的Dataset进行迭代,每笔数据以字典形式通过eval_fn()喂给模型,包含“input_ids”等内容,接着Evaluator又根据模型输出的“logits”求得真正的预测结果“pred”,输入给对应的Metric进行指标计算。
名称 |
描述 |
对应 |
描述 |
|---|---|---|---|
Evaluator |
所有Evaluator的基类 |
BaseMetric |
所有Metric的基类 |
EvaluatorForPerplexity |
评测LLM语言建模困惑度 |
PPLMetric |
收集LLM语言建模困惑度 |
EvaluatorForClassfication |
评测LLM执行分类任务 |
AccuracyMetric |
计算LLM分类的正确率 |
ClassifyFPreRecMetric |
计算LLM分类的查准查全率和F值 |
||
EvaluatorForGeneration |
评测LLM执行生成任务 |
DecodeMetric |
直接输出解码结果 |
BleuMetric |
计算LLM生成的BLEU值 |
||
RougeMetric |
计算LLM生成的Rouge值 |
EvaluatorForClassification 针对分类任务,对应数据集 CollieDatasetForClassfication。需要注意的是,虽然 CollieDatasetForClassfication 有两种输出,但是却在 EvaluatorForClassification 内部得到统一:即对于harness形式的处理,选择困惑度最小的候选答案序号作为“pred”,对于helm形式的处理,选择严格匹配的候选答案序号作为“pred”,如果预测答案不在候选答案列表中则“pred”设为-1。与模型预测结果“pred”相对的是数据dict中保存正确答案的字段“target”,Metric通过输入“pred”和“target”计算最终评测结果。EvaluatorForClassification 对应评测指标 AccuracyMetric和ClassifyFPreRecMetric,其含义无需赘述。
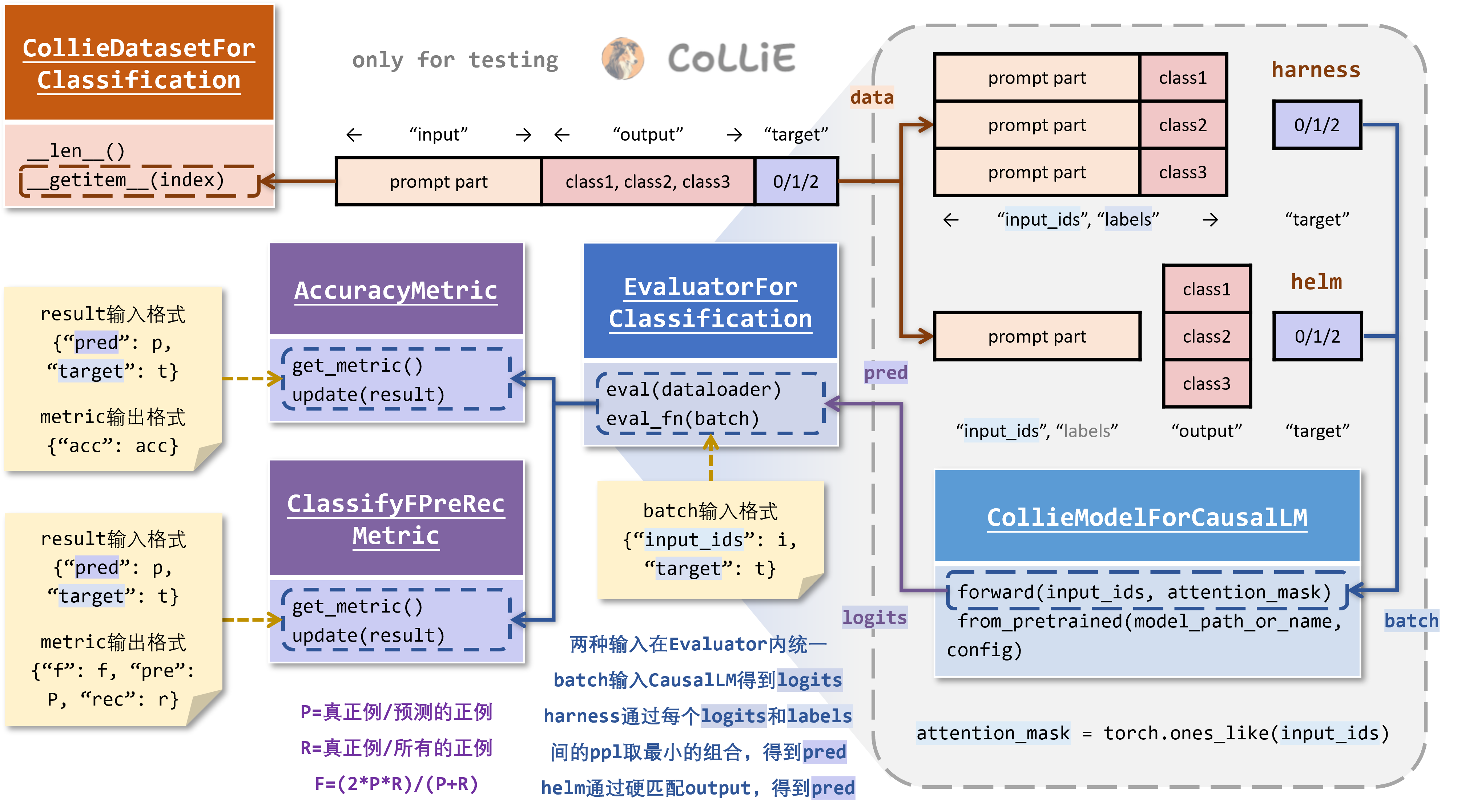
EvaluatorForGeneration 针对生成任务,对应数据集 CollieDatasetForGeneration,通过对模型输出“logits”在词表维度上取最大值得到“pred”;对应评测指标 包括 DecodeMetric、BleuMetric、RougeMetric。DecodeMetric只需要输入“pred”即可,直接解码打印模型输出结果,或将之保存至指定文件。BleuMetric和RougeMetric则是NLP中根据单词匹配结果判断生成文本质量的评测指标,其含义在此不多赘述。

EvaluatorForPerplexity只与数据集CollieDatasetForPerplexity和评测指标PPLMetirc相对应,计算模型语言建模困惑度。这里有两点需要注意:一方面,对于指令微调数据,计算困惑度不考虑其指令部分,即 CollieDatasetForPerplexity第二种输入的“input”字段;另一方面,EvaluatorForPerplexity 在内部就已经根据“logits”和“target”计算完成困惑度,PPLMetric仅作为“ppl”的收集模块,无需接收“pred”参数。

我们在这里给出在tutorial-1中省略的有关评测部分的示例代码。需要注意的是,初始化Evaluator时需要传入 模型model、配置类config(config无处不在)、评测数据集 dataset、监控器 monitor、对应具体指标字典 metrics;对于EvaluatorForGeneration,还需要传入tokenizer。对于评测指标字典 metrics,同一个Evaluator可以传入多个对应的Metric,只有传入metrics,evaluator才能够进行对应的评测;传入metrics时,可以通过字典的字段名称区分评测过程中打印的评测结果。
from collie import PPLMetric, DecodeMetric
from collie import EvaluatorForPerplexity, EvaluatorForGeneration
evaluator_ppl = EvaluatorForPerplexity(
model=model, config=config, dataset=eval_dataset,
monitors=[EvalMonitor(config), ], metrics={'ppl': PPLMetric(), }
)
evaluator_decode = EvaluatorForGeneration(
model=model, config=config, tokenizer=tokenizer, dataset=eval_dataset,
monitors=[EvalMonitor(config), ], metrics={'decode': DecodeMetric(), }
)
evaluator 既可以传入 trainer 来在训练中评测,也可以单独使用:
evaluator_ppl.eval()
evaluator_decode.eval()
3.4 CoLLiE 的 Trainer 模块¶
在上文介绍的Config、Evaluator等的基础上,我们可以完善tutorial-1中,trainer的示例代码;同时这里也将默认的loss,即经过GPTLMLoss封装的torch.nn.CrossEntropyLoss,呈现了出来。Trainer初始化之后,通过trainer.train()就可以实现这个训练,通过trainer.save_model()就可以把模型的权重等内容保存到对应文件夹目录下,参数权重保存在pytorch_model.bin中,兼容其他框架,可以直接用huggingface加载。
from collie import Trainer, GPTLMLoss
trainer = Trainer(
model=model, config=config, loss_fn=GPTLMLoss(-100),
optimizer=optimizer, lr_scheduler=lr_scheduler,
train_dataset=train_dataset, evaluators=[evaluator_ppl, evaluator_decode],
monitors=[LRMonitor(config), LossMonitor(config)],
)
trainer.train()
trainer.save_model("./result")
除了上述应用到的初始化参数,其他较为重要的Trainer初始化参数如下表所示。除了model、config,其他的参数CoLLiE都允许默认为None;例如optimizer、 lr_scheduler,这些都可以在Trainer中设为None,并在配置类config中的“ds_config”进行设置,书写格式同deepspeed使用。此外,此处的optimizer可以使用pytorch定义的经典优化器,如Adam,也可以使用CoLLiE自定义的高效优化器,如AdaLomo,详见 tutorial-5。
名称 |
描述 |
|---|---|
model |
待训练模型,一般是 ColliModelForCausalLM 类型 |
config |
训练配置参数,即初始化之后的 CollieConfig |
tokenizer |
模型对应分词器,若传入,要求是 PreTrainedTokenizerBase 类型 |
loss_fn |
损失函数,默认 GPTLMLoss(),即 封装后的 nn.CrossEntropyLoss() |
train_fn |
训练函数,默认 None,允许传入自定义函数控制训练过程 |
eval_fn |
评测函数,默认 None,允许传入自定义函数控制评测过程 |
optimizer |
优化器,默认 None,CoLLiE 实现 LOMO 优化器 详见 tutorial-5 |
lr_scheduler |
优化器控制,默认 None,参考 torch.optim.lr_scheduler |
train_dataset |
训练数据集,torch.utils.data.Dataset 或 CollieDatasetForTraining 类型 |
eval_dataset |
训练数据集,torch.utils.data.Dataset 或 CollieDatasetForTraining 类型 |
callbacks |
回调函数列表,自定义模型训练过程,详见 tutorial-4 |
train_dataset_collate_fn |
负责训练数据padding的函数,默认 ColliePadder() |
eval_dataset_collate_fn |
负责训练测试padding的函数,默认 ColliePadder(padding_left=True) |
data_provider |
数据提供器,默认 None,BaseProvider 类型,详见 tutorial-4 |
monitors |
监控器列表,默认 None,BaseMonitor 类型,详见 tutorial-4 |
metrics |
评测指标字典,例如 {'acc': AccuracyMetric()} |
evaluators |
评测模块列表,例如 [EvaluatorForClassfication(), ] |